

Intro to Retrieval Augmented Generation for Engineers
TL;DR
Preparing a CEO for a tech strategy meeting with the latest trends is like using Retrieval Augmented Generation (RAG) for language models. RAG updates the model with current information right before it responds, ensuring it delivers timely and accurate answers, much like arming a CEO with the most recent insights for informed decision-making.
Introduction
You’ve been prompting models left and right but have started to notice that the quality of the answers you’re getting back degrades the more relevant to today your questions become. You know you can tweak your prompts to give the model enough context for your query but that gets too tedious quickly, and, quite frankly, it is not conducive to a good user experience.
Enter the world of Retrieval Augmented Generation (RAG), an approach to prompting that can help you add facts and up-to-date knowledge to your Large Language Model (LLM) for more accurate and current responses.
Before we go into RAG, let’s describe LLMs to set the scene. At their core, LLMs learn from vast amounts of text, predicting what comes next in a sentence. This learning happens in stages—from initial broad learning to more focused fine-tuning, and sometimes, additional adjustments to hone in on specific styles or tasks. However, these models have a significant limitation: their training data is static and becomes outdated over time. So, how can we continue to extract value from a model without having to constantly retrain it (which may require you to rob a bank)?

Enter RAG
RAG tackles the limitations of LLMs by integrating current, relevant information into prompts, effectively enhancing a model’s responses. This technique not only keeps the model up-to-date without constant retraining but it also allows for customization and privacy control over the added data. It’s a strategic way to maintain a model’s relevancy and accuracy over time.
Here’s an instance of what happens when we ask a question that involves having access to information beyond the cut-off date of the training data.
truss predict --model my-mistral-7B-instruct -d '{"prompt": "What \
were some of the main topics on Motion Design \
discussed on different podcasts such as, the school \
of motion design podcast, on the first week of \
February 2024?", "max_new_tokens": 600}'
Calling predict on development deployment ID qrpd003...
"<s><s> [INST] What were some of the main topics on Motion Design discussed
on different podcasts such as, the school of motion design podcast, on the
first week of February 2024? [/INST] I cannot provide information on specific
podcasts as they are subject to change and are not available in my knowledge
base. Please specify the name of the podcast you are referring to.</s>"
The examples above can be fixed with a bit of non-fancy RAG using the description of the latest podcast of the School of Motion.
truss predict --model my-mistral-7B-instruct -d '{"prompt": "What were some \
of the main topics on Motion Design....?
Here is some context to help you answer the prompt: \
----
In this weeks podcast, we chat with Jerry Liu—Creative \
Director at Rive and a man who has seen a lot in his \
prolific motion design career. He has done plenty of studio \
work, a stint at Meta, made 7-figures selling NFTs (!!!), \
and is now deep in the fast-growing... \
---",
"max_new_tokens": 600}'
Calling predict on development deployment ID qrpd003...
"<s><s> [INST] What were some of the main topics on Motion Design...[/INST]
In addition to the discussion about Rive and its impact on motion
design, some other topics that may have been discussed on the School
of Motion Design podcast in the first week of February 2024 could
include:\n\n1. Trends and developments in the motion design industry\n2.
Best practices for creating effective and engaging motion design\n3.
Overview of new and emerging technologies that are changing the way
motion design is created and delivered\n4. Tips and advice for motion
designers looking to improve their skills and advance their careers\n5.
Discussion of the role of creativity and innovation in the motion design process."
While the example above is quite straightforward, it helps to put into context how we can use RAG without custom tools by directly injecting relevant information into the prompt. But, of course, RAG can also be done more efficiently with a bit of code and specialized frameworks like llama_index. For example, the aim of the example below is to have a set of abstractions that help you (1 & 2) load different pieces of data while splitting them into chunks, (1 & 3) create an embedding vector for each chunk while indexing these vectors in an in-memory vector store, and, finally, (4 & 5) query the default LLM under the hood (GPT-3.5-Turbo) while inserting information about the data of interest into the prompt.
mkdir -p 'data/'
wget 'https://somewhere.com/paul_graham/paul_graham_essay.txt' \
-O 'data/paul_graham_essay.txt'
from llama_index import VectorStoreIndex, SimpleDirectoryReader # (1)
documents = SimpleDirectoryReader("data").load_data() # (2)
index = VectorStoreIndex.from_documents(documents) # (3)
query_engine = index.as_query_engine() # (4)
response = query_engine.query("What did the author do growing up?") # (5)
print(response)
The author wrote short stories and also worked on programming, specifically on an IBM 1401 computer in 9th grade. They later got a microcomputer, a TRS-80, and started programming more extensively, including writing simple games and a word processor.
Once we have a useful set of abstractions like the ones above, what we want to do is to find a way to automate our implementation of RAG with custom code or tools like langchain.
Now that we know what RAG is, let’s go over a bit more details on how things work.
How Does RAG Work?
Say you, a software engineer, have been tasked with creating an intelligent chatbot that can answer any question about X topic in your platform. Because the budget of your project is low, you can discard the option of training an LLM from scratch using an open-source pile of data plus your own. Therefore, two options that can get you to a working prototype relatively quickly are: (1) fine-tune an open-source model on your company’s data, or (2) create an ML system with RAG. To keep up with our theme here, we’ll go for the latter.
The modern RAG-enabled AI system you need to build will require a few ingredients.
- An LLM: You’ll need one of these to get the job done, and open-source ones will give you the best bang for your buck. 😉
- An Embedding model: A model for creating vector embeddings transforms words, phrases, or documents into numerical vectors, capturing the semantic meaning, relationships, and context of the text in a high-dimensional space. This model can, potentially, be the same LLM you’re using for Q&A but it might not be necessary to take this route. (Check out this article to learn more about how to deploy open-source embedding models, or this page to deploy your own with one click.)
- Out-of-sample data: The information your model doesn’t know anything about but it should (e.g. your company’s data).
- A Vector Database: A place to store the embedding representations and index of your out-of-sample data.
- A UI: No need to go fancy here for the POC, gradio, streamlit, or nicegui would suffice.
Starting with a straightforward system architecture, here is what our application will look like.
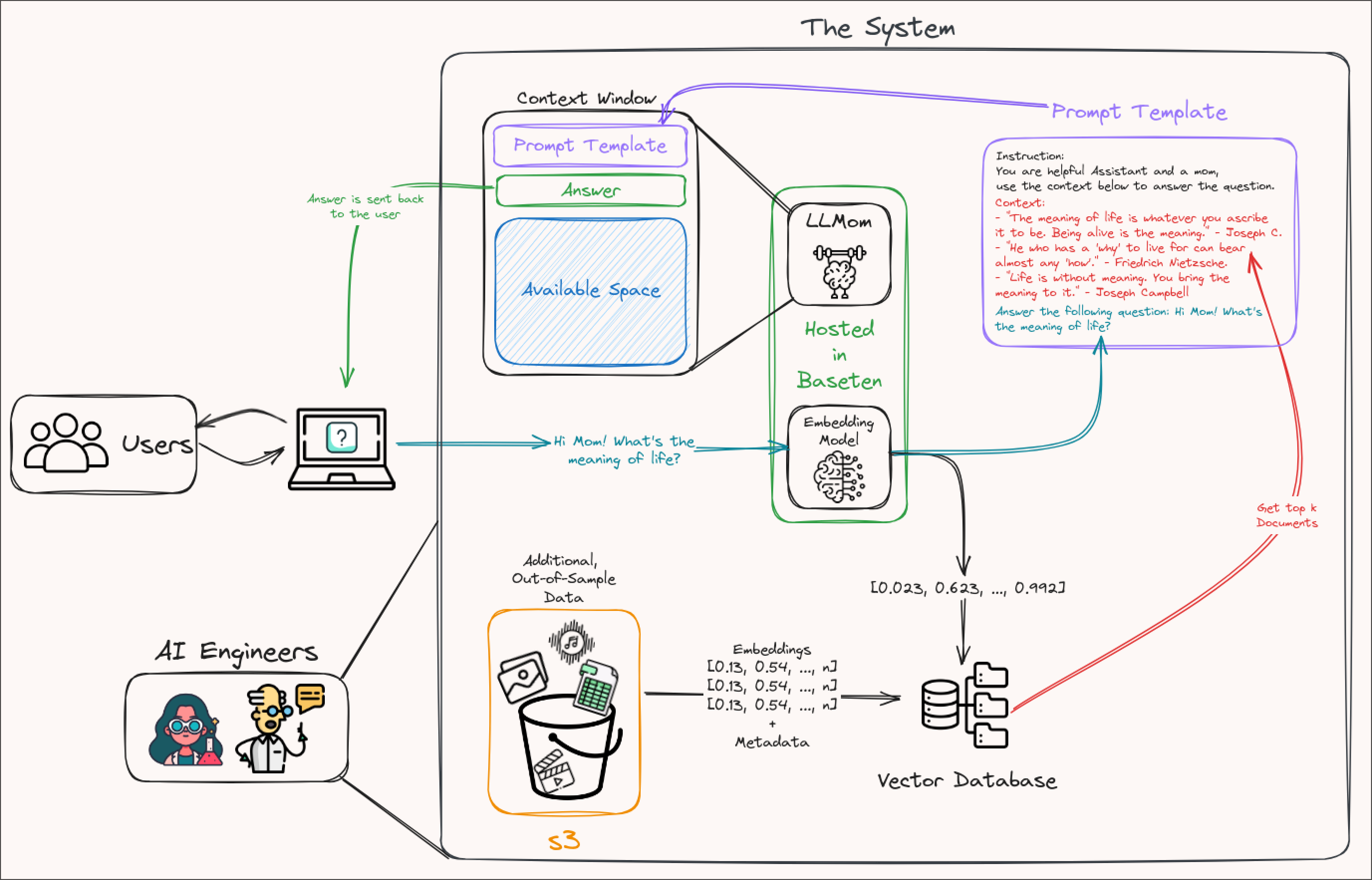
A user will come to our platform (the UI) to get instructions to prompts such as (1) write some code to make X feature using this new Python framework, (2) create a meal recipe similar to the one Ramsey created in his TV show last week, (3) write a concise and snarky email response based on this thread. An instruction will then be used in two ways. First, it will pass through the embedding model to be converted into a vector that we’ll then use alongside a vector database to find the most similar and relevant documents in our out-of-sample data. Second, the query will be added to a prompt template alongside the most similar documents retrieved from the vector database or our s3 bucket. Finally, the completed prompt template will be given to our LLM (say, Mistral 7B) so that it can do its magic.
Before converting our questions into an embedding vector, we need to go through the process of converting our out-of-sample data into embedding vectors and adding these into a vector database. Ideally, the vector database will offer a convenient SDK, some similarity metrics to choose from, and the ability to store metadata alongside each vector (e.g., the URL to the document inside an s3 bucket or the document itself, the date when the document was created, the length, the topic, etc.).
Even though it might be tempting to use the same LLM for instructions to create embedding vectors of your documents, this might be a sub-optimal choice. It can (1) get quite expensive to convert all of your data into embedding vectors if you’re using a state-of-the-art, closed-source model, (2) the high dimensionality of the vectors might slow down the look-up process, (3) if your LLM is not open-source, the moment that LLM is discontinued, you lose the ability to generate the same representation of your historical data for your new data, so please keep these in mind.
Now that we know how RAG works and how to think about it at a systems level, let’s look at the different ways in which we can use it.
Strategies & Caveats
RAG comes in many flavors and it is important to understand at least some of these to use it effectively.
Chunking
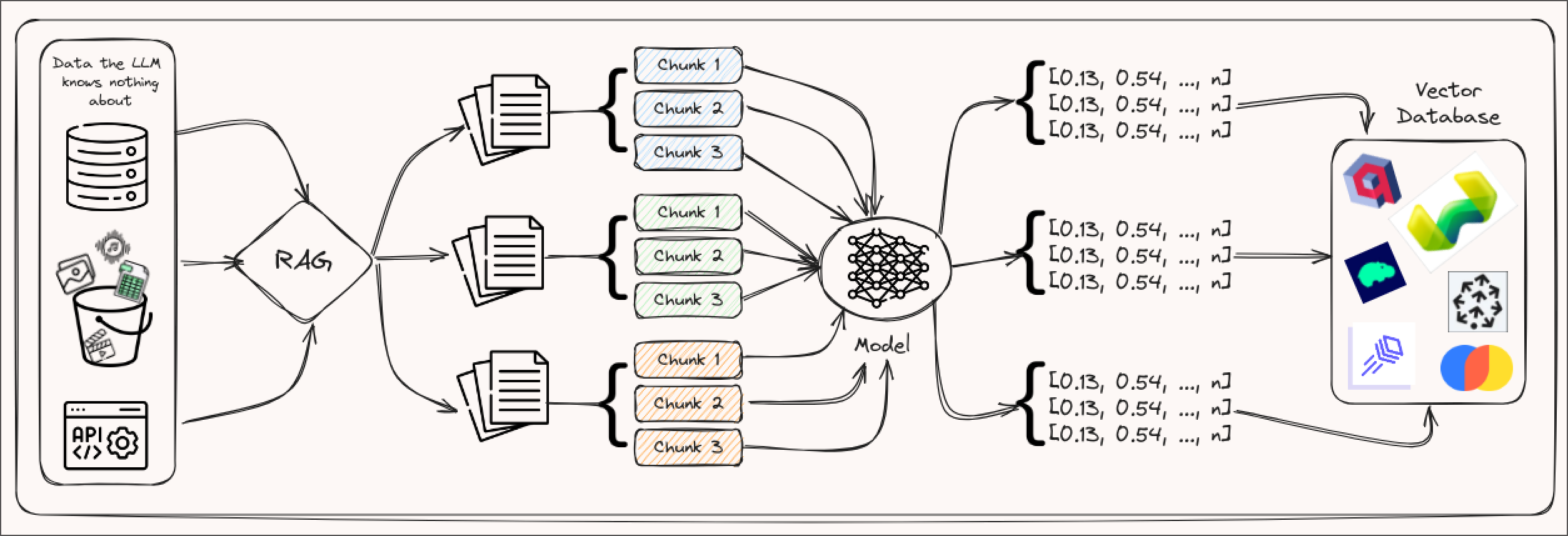
The first strategy involves splitting your documents into different chunks, creating an embedding for each of these chunks, and then storing the vectors (and potentially the document as well) inside a vector database to retrieve them when needed. These chunks can be of different sizes, for example, phrases, paragraphs, sections, and chapters. The caveat here is that the shorter the chunk the more noise you might add to your template.
Full Document
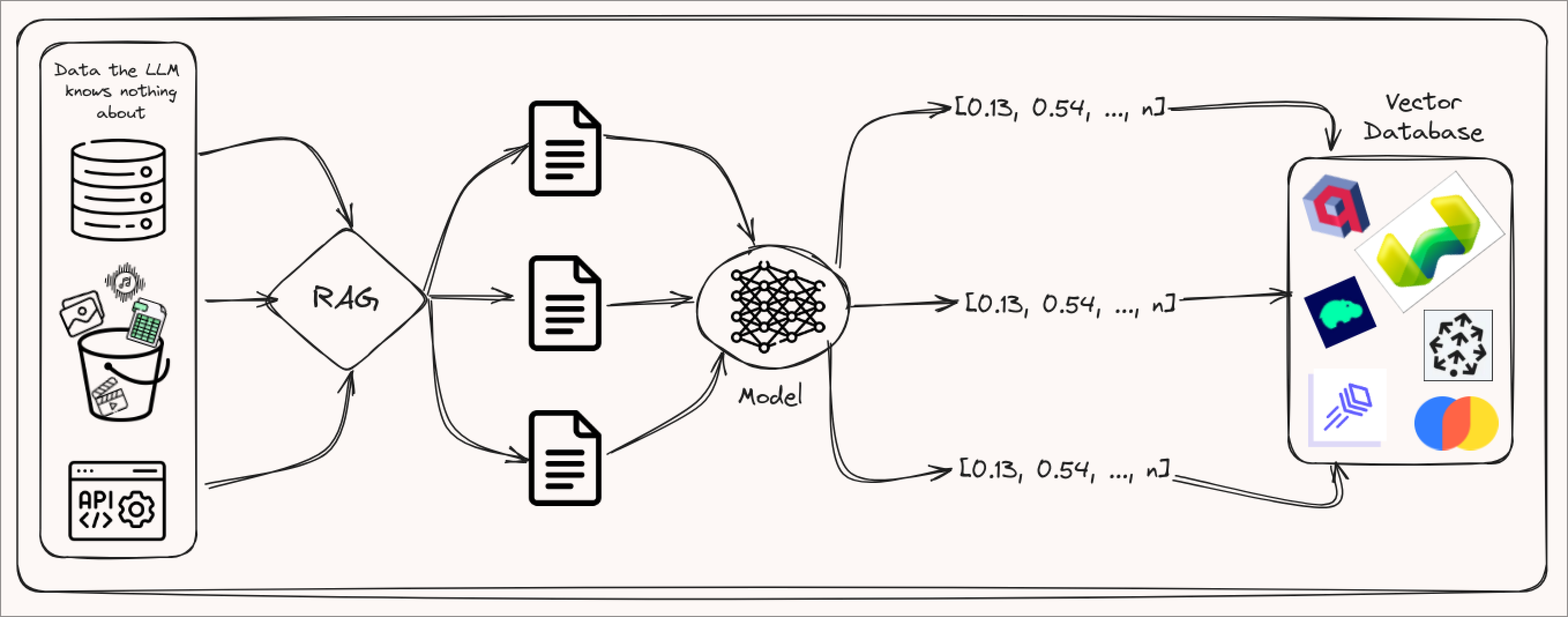
Another approach is to embed the full documents into the prompt template if the context window of your LLM is big enough. This approach is often not ideal, though. If your user is going to have continuous interactions with your LLM, then the context window will fill up quite quickly. Conversely, if these are single or short interactions where the more information your LLM has the better it responds, then including the whole document makes more sense.
Summarizer
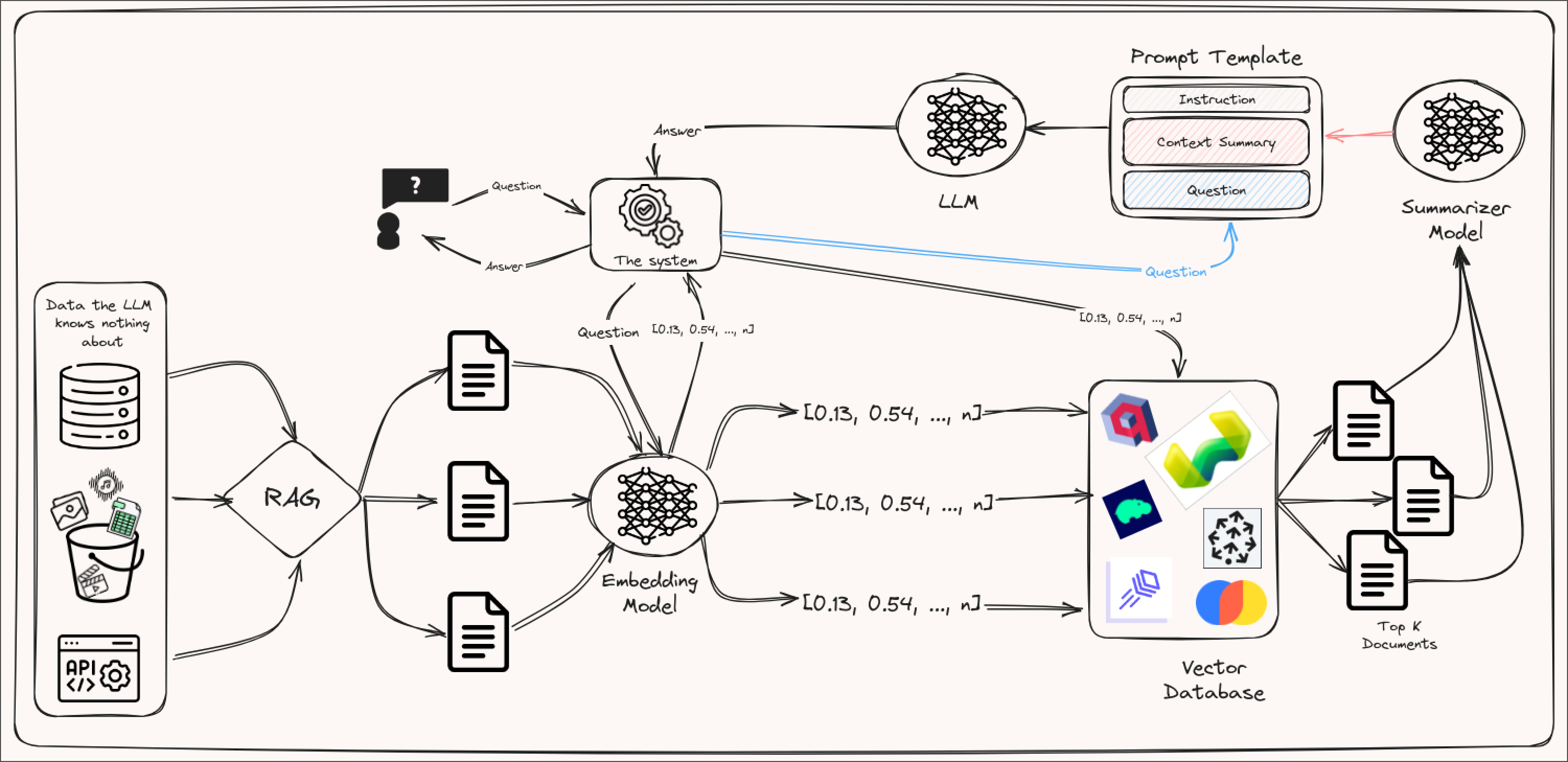
An approach adjacent to the full-document one involves attaching a summarizer model to your pipeline. For example, if you are already retrieving full documents, you could add the summary of these documents as the context to your prompt rather than the full documents. This can give your LLM enough information to accurately accomplish a task without exhausting the context window as quickly. The caveat of this approach is that adding another model to your pipeline might increase the latency of a response and hurt the user experience.
Re-ranking
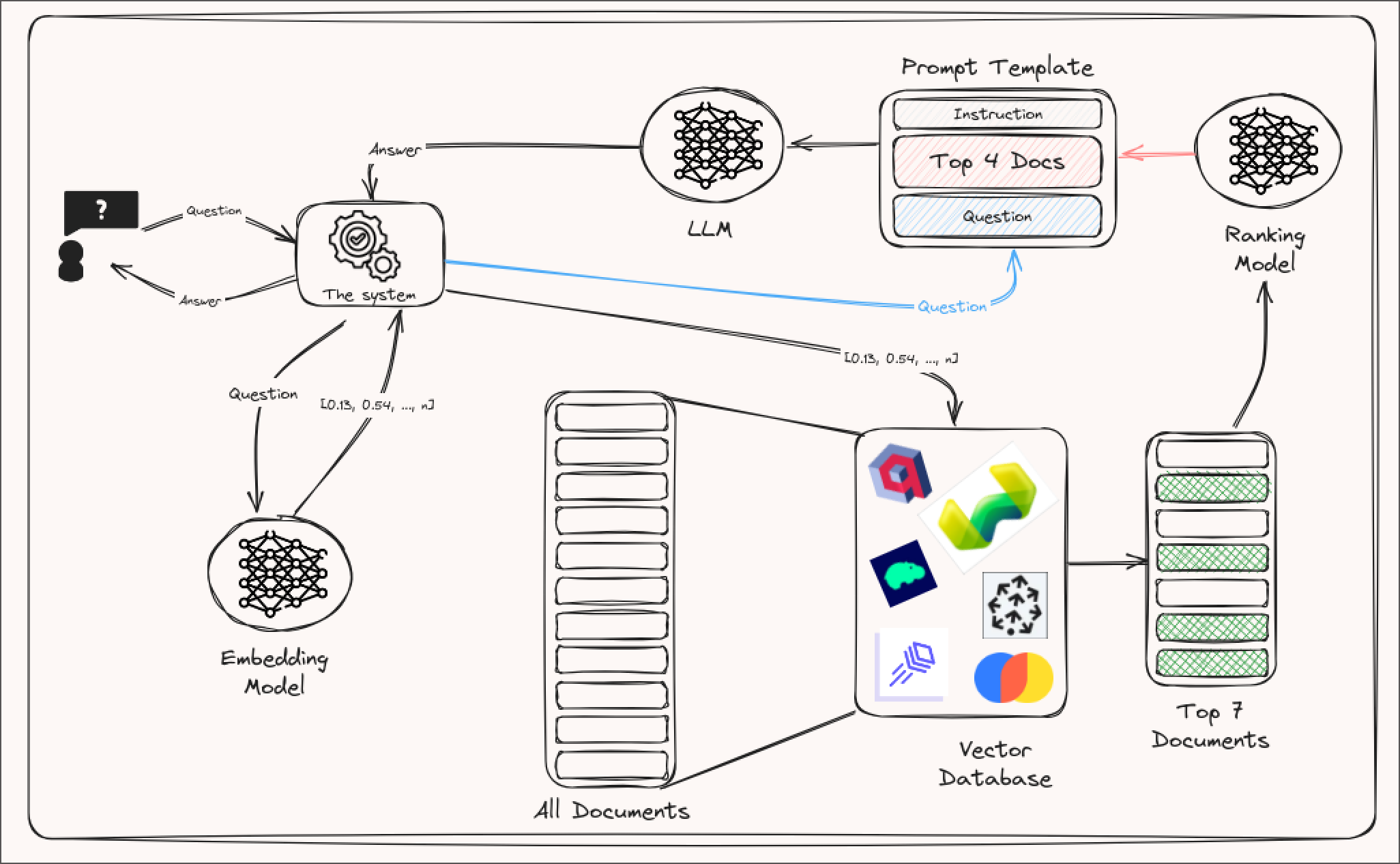
A very popular approach to RAG involves re-ranking, which refers to the process of reordering or prioritizing retrieved documents or passages based on their relevance to a prompt. After retrieving relevant information, the ranking model will evaluate and reorder the retrieved results to ensure that the most contextually fitting pieces of information get passed in as context. The caveat is that adding a reranker might increase the latency of the system, or prioritize relevance instead of novelty.
There are a few other approaches including keyword matching, RAG + HyDE, Sparse Retrieval, Dense Retrieval, Query Pipelines, and more. We won’t go into detail on these but do hope you keep these in mind in case you need a more unique approach to RAG in your AI system.
Takeaway
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by feeding them up-to-date, relevant information, similar to providing a CEO with the latest insights for key decisions. This technique involves creating text embeddings from a corpus, storing these embeddings in a vector database like Qdrant for efficient retrieval, and appending this information to the LLM’s prompts. This approach ensures LLMs offer precise, current, and context-rich responses. Implementing RAG effectively requires LLMs with large context windows, such as Mistral 7B or Mixtral 8x7B. Baseten significantly facilitates this process by hosting text embedding models and LLMs, and supporting the construction of RAG pipelines with Truss, streamlining the integration of real-time data into LLMs for improved output.
